Multiclass Classification in Vanguard¶
[1]:
# © Crown Copyright GCHQ
#
# Licensed under the GNU General Public License, version 3 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.gnu.org/licenses/gpl-3.0.en.html
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
A showcase of the implementation of standard multiclass classification in Vanguard. This builds upon the binary classification example.
[2]:
random_seed = 1_989
[3]:
import numpy as np
from gpytorch.mlls import VariationalELBO
from matplotlib import pyplot as plt
from vanguard.classification import CategoricalClassification
from vanguard.classification.likelihoods import MultitaskBernoulliLikelihood, SoftmaxLikelihood
from vanguard.datasets.classification import MulticlassGaussianClassificationDataset
from vanguard.kernels import ScaledRBFKernel
from vanguard.multitask import Multitask
from vanguard.vanilla import GaussianGPController
from vanguard.variational import VariationalInference
Introduction¶
As seen in the binary classification example notebook, classification can rephrased as a regression problem fairly straightforwardly by treating class labels as points in the interval $[0, 1]$. At its most basic, multiclass classification can be thought of as an aggregation of individual binary classifiers for each class label, giving a score for each class. However, this is hardly a robust and principled solution. Firstly, the subsequent “probabilities” collected from each class predictor are unlikely to sum to 1. Secondly, this method would treat each class as independent which can be a dangerous assumption and hurt model accuracy. Luckily it is possible to overcome both of these problems with standard components from Vanguard and GPyTorch.
Data¶
We start with the MulticlassGaussianClassificationDataset for this experiment, which creates multiple classes based on the distance to the centre of a two-dimensional Gaussian distribution.
[4]:
NUM_CLASSES = 4
DATASET = MulticlassGaussianClassificationDataset(
num_train_points=100,
num_test_points=500,
num_classes=NUM_CLASSES,
covariance_scale=1,
rng=np.random.default_rng(random_seed),
)
[5]:
plt.figure(figsize=(8, 8))
DATASET.plot()
plt.show()

Binary Multitask Modelling¶
It is possible to overcome the issue of class dependence using the Multitask decorator, which tracks covariance between multiple regressors. Instead of using the BinaryClassification decorator directly, we instead use the CategoricalClassification decorator. Finally, recall that binary classification requires a BernoulliLikelihood to properly run inference. For multitask, we need to use the corresponding MultitaskBernoulliLikelihood, which will sum the log probabilities over the task dimension. As before, this requires us to use the VariationalInference decorator to enable approximate inference.
As described in the introduction, this initial simplistic approach uses Bernoulli likelihoods for each task of a multitask GP. As mentioned, the resulting likelihood is improper, in that the probabilities for each class do not sum to 1, but the the “probabilities” for each class can be interpreted as the model’s confidence in that class. The closest analogy would be a more probabilistically principled version of the logits of a neural network classifier. Note that the tasks are not completely independent, due to the multitask GP structure.
[6]:
@CategoricalClassification(num_classes=NUM_CLASSES, ignore_all=True)
@Multitask(num_tasks=NUM_CLASSES, ignore_all=True)
@VariationalInference(ignore_all=True)
class CategoricalMultitaskClassifier(GaussianGPController):
pass
We will use a ScaledRBFKernel. Note that we do not pass the model the standard train_y, but the special one_hot_train_y which encodes the target class labels into one-hot vectors to more easily enable multitask.
[7]:
controller = CategoricalMultitaskClassifier(
DATASET.train_x,
DATASET.one_hot_train_y,
ScaledRBFKernel,
y_std=0,
likelihood_class=MultitaskBernoulliLikelihood,
marginal_log_likelihood_class=VariationalELBO,
rng=np.random.default_rng(random_seed),
)
/home/docs/checkouts/readthedocs.org/user_builds/vanguard/envs/latest/lib/python3.13/site-packages/torch/utils/_device.py:104: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).
return func(*args, **kwargs)
Before we try fitting, let’s see how well the classifier does without any hyperparameter training. We cannot use the posterior_over_point() method, as the model posteriors need to be passed through the likelihood. Instead, classifiers in Vanguard have a special classify_points method to do this.
[8]:
predictions, probs = controller.classify_points(DATASET.test_x)
[9]:
plt.figure(figsize=(8, 8))
DATASET.plot_prediction(predictions)
plt.show()

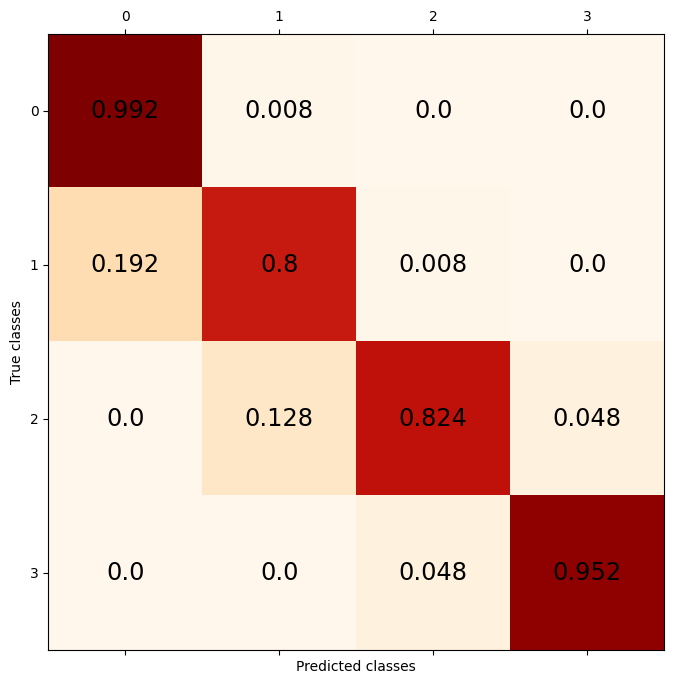
In the above plot, the fill colour of a point denotes the predicted class, whereas the edge colour denotes the correct class. As we can plainly see, the model isn’t very good without being trained. However, a small amount of fitting will improve things immensely:
[10]:
controller.fit(100)
predictions, probs = controller.classify_points(DATASET.test_x)
[11]:
plt.figure(figsize=(8, 8))
DATASET.plot_prediction(predictions)
plt.show()
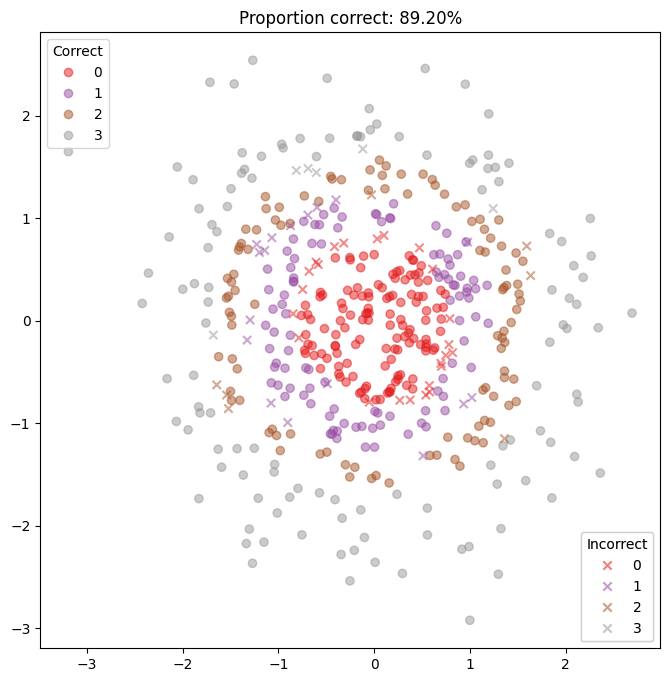
It may be helpful to look at a confusion matrix:
[12]:
plt.figure(figsize=(8, 8))
DATASET.plot_confusion_matrix(predictions)
plt.show()
The default variational strategy for multitask GPs approximates the posterior as entirely independent single-task GPs. There is an alternative, namely linear model co-regionalisation (LMC) [Wackernagel03], which can be used simply by providing the number of latent dimensions to the Multitask decorator. The resulting models should be able to achieve superior classification accuracies when trained.
[13]:
NUM_LATENTS = 10
@CategoricalClassification(num_classes=NUM_CLASSES, ignore_all=True)
@Multitask(num_tasks=NUM_CLASSES, lmc_dimension=NUM_LATENTS, ignore_all=True)
@VariationalInference(ignore_all=True)
class CategoricalMultitaskClassifier(GaussianGPController):
pass
[14]:
controller = CategoricalMultitaskClassifier(
DATASET.train_x,
DATASET.one_hot_train_y,
ScaledRBFKernel,
y_std=0,
likelihood_class=MultitaskBernoulliLikelihood,
marginal_log_likelihood_class=VariationalELBO,
rng=np.random.default_rng(random_seed),
)
/home/docs/checkouts/readthedocs.org/user_builds/vanguard/envs/latest/lib/python3.13/site-packages/torch/utils/_device.py:104: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).
return func(*args, **kwargs)
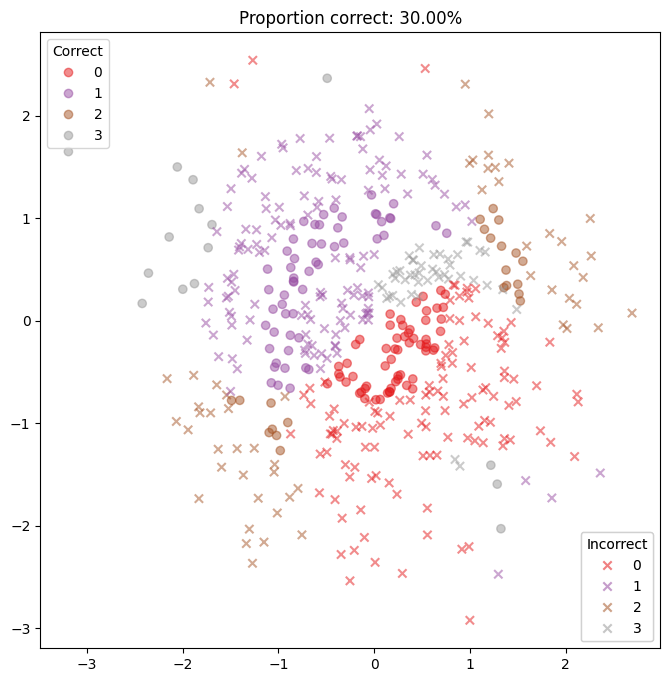
Again, let’s see how well the classifier does without any hyperparameter training.
[15]:
predictions, probs = controller.classify_points(DATASET.test_x)
[16]:
plt.figure(figsize=(8, 8))
DATASET.plot_prediction(predictions)
plt.show()
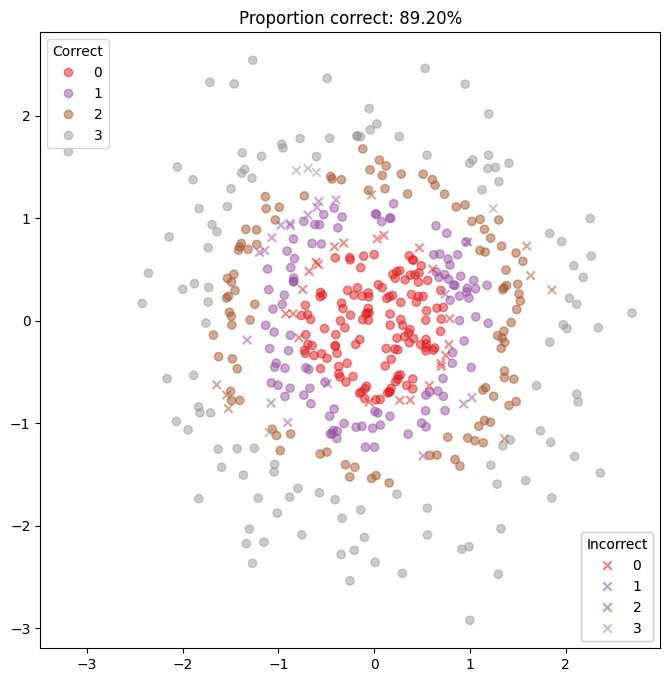
[17]:
controller.fit(100)
predictions, probs = controller.classify_points(DATASET.test_x)
[18]:
plt.figure(figsize=(8, 8))
DATASET.plot_prediction(predictions)
plt.show()
[19]:
plt.figure(figsize=(8, 8))
DATASET.plot_confusion_matrix(predictions)
plt.show()

LMC is not necessarily immediately superior to the simpler strategy, but with sufficient tuning we expect it to become so.
Softmax Multiclass Modelling¶
A more robust choice of likelihood is the SoftmaxLikelihood. Instead of simply summing the log probabilities, we use the softmax function:
[20]:
NUM_LATENTS = 10
NUM_FEATURES = 6
@CategoricalClassification(num_classes=NUM_CLASSES, ignore_all=True)
@Multitask(num_tasks=NUM_FEATURES, lmc_dimension=NUM_LATENTS, ignore_all=True)
@VariationalInference(ignore_all=True)
class CategoricalSoftmaxMultitaskClassifier(GaussianGPController):
pass
When using softmax, we no longer use the one-hot encoded vectors, and instead return to the train_y attribute.
[21]:
controller = CategoricalSoftmaxMultitaskClassifier(
DATASET.train_x,
DATASET.train_y,
ScaledRBFKernel,
y_std=0,
likelihood_class=SoftmaxLikelihood,
marginal_log_likelihood_class=VariationalELBO,
rng=np.random.default_rng(random_seed),
)
/home/docs/checkouts/readthedocs.org/user_builds/vanguard/envs/latest/lib/python3.13/site-packages/torch/utils/_device.py:104: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).
return func(*args, **kwargs)
[22]:
controller.fit(100)
predictions, probs = controller.classify_points(DATASET.test_x)
[23]:
plt.figure(figsize=(8, 8))
DATASET.plot_prediction(predictions)
plt.show()

[24]:
plt.figure(figsize=(8, 8))
DATASET.plot_confusion_matrix(predictions)
plt.show()

Conclusions¶
Multi-class classification with Gaussian processes does not perform as well as other machine learning techniques like neural networks, but it does require fewer parameters to get decent results. Although larger amounts of data will not scale well, the use of variational inference allows us to mitigate this somewhat. Ultimately, the contents of this notebook act more as a research showcase than a recommended method for classification, but more advanced features for scalability (such as distributed GPs) could lead to more plausible use cases in the future.