Synthetic Data¶
Synthetic data is particularly useful when running tests, as the data can be specifically cultivated for one’s needs.
- class vanguard.datasets.synthetic.SyntheticDataset(functions=(<function simple_f>, ), output_noise=0.1, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Bases:
DatasetSynthetic data with homoskedastic noise for testing.
- Parameters:
functions (
Iterable[Callable[[ndarray[tuple[Any,...],dtype[floating]]],ndarray[tuple[Any,...],dtype[floating]]]]) – The functions to be used to generate the synthetic data. If multiple functions are given, a multidimensional output is generated.output_noise (
float) – The standard deviation for the output standard deviation, defaults to 0.1. Only applied to the training data; the testing data has no output noise actually applied, but we still set test_y_std = output_noise.train_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the training input. Defaults to (0.01, 0.05).test_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the testing input. Defaults to (0.01, 0.03).n_train_points (
int) – The total number of training points.n_test_points (
int) – The total number of testing points.significance (
float) – The significance to be used.rng (
Optional[Generator]) – Generator instance used to generate random numbers.
- __init__(functions=(<function simple_f>, ), output_noise=0.1, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Initialise self.
- make_sample_data(n_points, input_noise_bounds, output_noise_level, interval_length=1)[source]¶
Create some sample data.
- Parameters:
n_points (
int) – The number of points to create.input_noise_bounds (
tuple[float,float]) – The lower, upper bounds for the resulting input noise.output_noise_level (
Union[int,float]) – The amount of noise applied to the outputs.interval_length (
float) – Use to scale the exact image of the function, defaults to 1.
- Return type:
tuple[tuple[ndarray[tuple[Any,...],dtype[floating]],ndarray[tuple[Any,...],dtype[floating]]],ndarray[tuple[Any,...],dtype[floating]]]- Returns:
The output and the mean and standard deviation of the input, in the form
(x_mean, x_std), y.
- class vanguard.datasets.synthetic.HeteroskedasticSyntheticDataset(functions=(<function simple_f>, ), output_noise_mean=0.1, output_noise_std=0.01, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Bases:
SyntheticDatasetSynthetic data with heteroskedastic noise for testing.
The
train_y_stdandtest_y_stdattributes are created by drawing from a normal distribution centred on the value of theoutput_noiseparameter.- Parameters:
functions (
Iterable[Callable[[ndarray[tuple[Any,...],dtype[floating]]],ndarray[tuple[Any,...],dtype[floating]]]]) – The functions to be used to generate the synthetic data.output_noise_mean (
float) – The mean for the output standard deviation, defaults to 0.1.output_noise_std (
float) – The standard deviation for the output standard deviation, defaults to 0.01.train_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the training input. Defaults to (0.01, 0.05).test_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the testing input. Defaults to (0.01, 0.03).n_train_points (
int) – The total number of training points.n_test_points (
int) – The total number of testing points.significance (
float) – The significance to be used.rng (
Optional[Generator]) – Generator instance used to generate random numbers.
- __init__(functions=(<function simple_f>, ), output_noise_mean=0.1, output_noise_std=0.01, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Initialise self.
- class vanguard.datasets.synthetic.HigherRankSyntheticDataset(functions=(<function simple_f>, ), output_noise=0.1, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Bases:
DatasetSynthetic data with rank 2 input features. In this case each x is a 2x2 matrix.
- Parameters:
functions (
Iterable[Callable[[ndarray[tuple[Any,...],dtype[floating]]],ndarray[tuple[Any,...],dtype[floating]]]]) – The functions to be used to generate the synthetic data.output_noise (
float) – The standard deviation for the output standard deviation, defaults to 0.1.train_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the training input. Defaults to (0.01, 0.05).test_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the testing input. Defaults to (0.01, 0.03).n_train_points (
int) – The total number of training points.n_test_points (
int) – The total number of testing points.significance (
float) – The significance to be used.rng (
Optional[Generator]) – Generator instance used to generate random numbers.
- __init__(functions=(<function simple_f>, ), output_noise=0.1, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Initialise self.
- make_sample_data(n_points, input_noise_bounds, output_noise_level, interval_length=1)[source]¶
Create some sample data.
- Parameters:
n_points (
int) – The number of points to create.input_noise_bounds (
tuple[float,float]) – The lower, upper bounds for the resulting input noise.output_noise_level (
Union[int,float]) – The amount of noise applied to the inputs.interval_length (
float) – Use to scale the exact image of the function, defaults to 1.
- Return type:
tuple[tuple[ndarray[tuple[Any,...],dtype[floating]],ndarray[tuple[Any,...],dtype[floating]]],ndarray[tuple[Any,...],dtype[floating]]]- Returns:
The output and the mean and standard deviation of the input, in the form
(x_mean, x_std), y.
- class vanguard.datasets.synthetic.MultidimensionalSyntheticDataset(functions=(<function simple_f>, <function complicated_f>), output_noise=0.1, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Bases:
DatasetSynthetic data with multiple input dimensions.
- Parameters:
functions (
Iterable[Callable[[ndarray[tuple[Any,...],dtype[floating]]],ndarray[tuple[Any,...],dtype[floating]]]]) – The functions used on each input dimension (they are combined linearly to make a single output).output_noise (
float) – The standard deviation for the output standard deviation, defaults to 0.1. Only applied to the training data; the testing data has no output noise actually applied, but we still set test_y_std = output_noise.train_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the training input. Defaults to (0.01, 0.05).test_input_noise_bounds (
tuple[float,float]) – The lower, upper bounds of the linearly varying noise for the testing input. Defaults to (0.01, 0.03).n_train_points (
int) – The total number of training points.n_test_points (
int) – The total number of testing points.significance (
float) – The significance to be used.rng (
Optional[Generator]) – Generator instance used to generate random numbers.
- __init__(functions=(<function simple_f>, <function complicated_f>), output_noise=0.1, train_input_noise_bounds=(0.01, 0.05), test_input_noise_bounds=(0.01, 0.03), n_train_points=30, n_test_points=50, significance=0.025, rng=None)[source]¶
Initialise self.
The following functions are included as defaults for the previous class, although the class can be passed almost any function if required.
- vanguard.datasets.synthetic.simple_f(x)[source]¶
Map values through a simple equation.
\[f(x) = \sin(2\pi x)\]
- vanguard.datasets.synthetic.complicated_f(x)[source]¶
Map values through a complicated equation.
\[f(x) = -x^\frac{3}{2} + x\sin^2(2\pi x)\]
- vanguard.datasets.synthetic.very_complicated_f(x)[source]¶
Map values through a very complicated equation.
\[f(x) = -x^\frac{3}{2} + x\sin^2(2\pi x) + x^2 \cos(10\pi x)\]
Classification¶
- class vanguard.datasets.classification.BinaryStripeClassificationDataset(num_train_points, num_test_points, rng=None)[source]¶
Bases:
DatasetDataset comprised of one-dimensional input values, and binary output values (0 or 1).
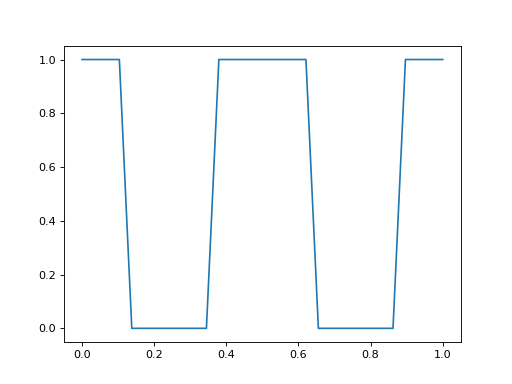
- Parameters:
- class vanguard.datasets.classification.BinaryGaussianClassificationDataset(num_train_points, num_test_points, *, covariance_scale=1.0, num_features=2, rng=None)[source]¶
Bases:
MulticlassGaussianClassificationDatasetA binary dataset based on
sklearn.datasets.make_gaussian_quantiles().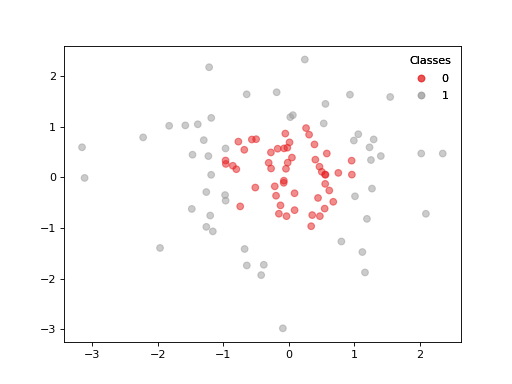
- Parameters:
num_train_points (
int) – The number of training points.num_test_points (
int) – The number of testing points.covariance_scale (
float) – The covariance matrix will be this value times the unit matrix. Defaults to 1.0.num_features (
int) – The number of features to generate for the input data.rng (
Optional[Generator]) – Generator instance used to generate random numbers.
- class vanguard.datasets.classification.MulticlassGaussianClassificationDataset(num_train_points, num_test_points, num_classes, *, covariance_scale=1.0, num_features=2, rng=None)[source]¶
Bases:
DatasetA multiclass dataset based on
sklearn.datasets.make_gaussian_quantiles().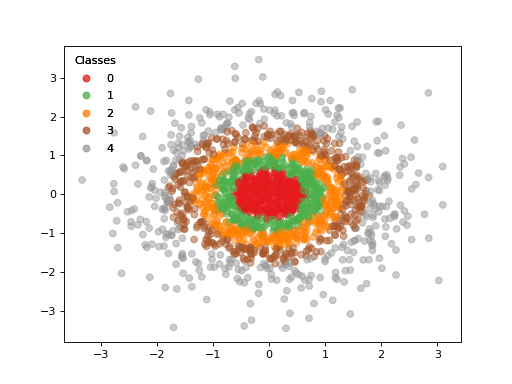
- Parameters:
num_train_points (
int) – The number of training points.num_test_points (
int) – The number of testing points.num_classes (
int) – The number of classes.num_features (
int) – The number of features to generate for the input data.covariance_scale (
float) – The covariance matrix will be this value times the unit matrix. Defaults to 1.0.rng (
Optional[Generator]) – Generator instance used to generate random numbers.
- __init__(num_train_points, num_test_points, num_classes, *, covariance_scale=1.0, num_features=2, rng=None)[source]¶
Initialise self.
- property one_hot_train_y: Tensor¶
Return the training data as a one-hot encoded array.
Note that if there are exactly two classes, this returns train_y.reshape((-1, 1)) instead.